Language is a medium through which we interact with other beings. When it comes to interacting with machines or computers, we have built different computer languages to program them.
Computers often need a translator to convert these languages written in human-readable form (high-level language) to computer-readable form (low-level language). Usually, this translation job is done by compilers and interpreters.
For example
- Java compiler converts Java code to Java Bytecode executable by the JVM (Java Virtual Machine).
- V8, the JavaScript engine from Google converts JavaScript code to machine code
- GCC can convert code written in programming languages like C, C++, Objective-C, Go among others to native machine code.
In very simple terms, the schematics of this translation looks something like this:

This compiler blackbox can be further divided into following stages:
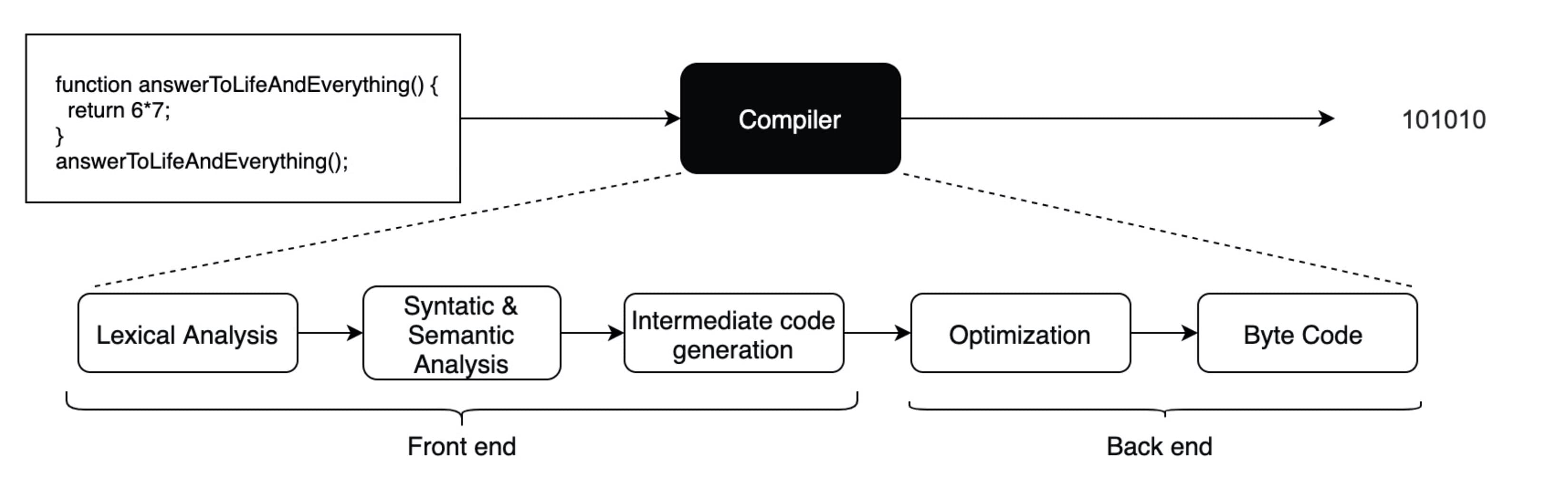
The front end phase generally include lexical analysis, syntax analysis, semantic analysis, and intermediate code generation while the back end includes optimization and machine code generation.
For this article, we will focus upon one of the major steps in almost all compiling pipelines - Abstract Syntax Trees.
Let’s understand some of the leading steps to build the AST from the input source code.
Lexical Analysis
In the Lexical analysis phase, the stream of characters from the input code is read by a scanner which breaks it down into the smallest parts which are called Lexemes. This part is language-agnostic, and what we end up with is a stripped-out version of our source text.
Next, these lexemes are passed on to the lexer/tokenizer, which turns those small representations of our source text into tokens, which are specific to the language in use. If the compiler encounters a string of characters for which it cannot create a token, it will stop its execution by throwing an error.
If the input is 6*(3+4), The lexer would contain rules to tell it that the characters *,+,(and)mark the start of a new token, so meaningless tokens like 6* or ( 3 will not be generated.
Following is an example of tokens from Esprima parser for JavaScript.
const esprima = require('esprima');
const program = 'answertoLifeAndEverything = 6 * 7';
esprima.tokenize(program);
/*
[
{ type: 'Keyword', value: 'const' },
{ type: 'Identifier', value: 'answertoLifeAndEverything' },
{ type: 'Punctuator', value: '=' },
{ type: 'Numeric', value: '6' },
{ type: 'Punctuator', value: '*' },
{ type: 'Numeric', value: '7' },
{ type: 'Punctuator', value: ';' },
];
*/The joint effort of the scanner and the tokenizer make up the lexical analysis of compilation.
Parsing
Once our input code has been tokenized, the resulting tokens are passed to the parser. The parser takes the source text and converts it into a tree data structure. This output from the parser is called a parse tree or abstract syntax tree.
Abstract Syntax Trees
Although, Parse Tree and Abstract Syntax Tree (AST) are two terms that are related and sometimes used interchangeably, the primary difference is in the level of abstraction.
The AST instead is a polished version of the parse tree, in which only the information relevant to understanding the code is maintained.

These useful data structures represent the abstract structure of source code regardless of the language. This is possible because, despite the syntactic differences, all languages have a very large overlap in terms of the code structure they express: variable assignment, conditions, logic branching, etc.
A great tool to better understand an AST is AST Explorer, where you can enter code and generate a real-time AST. This is an incredibly powerful way to introspect an AST, including the types of nodes and their properties.

AST in JavaScript
Following is a list of some famous parsers for JavaScript code. Most of them implement ESTree spec for the AST.
| Parser Name | AST |
|---|---|
| acorn | ESTree |
| babylon - (used in Bable) | Babel AST |
| esprima | ESTree |
| espree | ESTree |
| flow | ESTree + custom |
| TypeScript | Typescript AST |
All parsers work the same. Give it some code, get an AST.
// acorn
const { Parser } = require('acorn');
const ast = Parser.parse(readFileSync(fileName).toString());
// babel
const { parse } = require('@babel/parser');
const ast = parse('let foo = true;', {});
// esprima
const esprima = require('esprima');
const ast = esprima.parse('let foo = true;');AST Applications
Because of the abstract representation, AST can be used to convert one language to another, help developers write code in latest syntax and convert the code for legacy browsers in build time, empower IDEs to provide rich developer experience etc. Following are some of the major use cases.
Code Transpilation
Code transpilers are tools that help convert code written in one language to another.
Babel is one such toolchain that is mainly used to convert ECMAScript 2015+ code into a backward-compatible version of JavaScript in current and older browsers or environments. Here are the main things Babel can do:
- Transform syntax
- Polyfill features that are missing in the target environment (through @babel/polyfill)
- Source code transformations (codemods)
- Transform JSX to JS
At a high level, it has 3 stages: parsing, transforming, and generation. You give Babel some JavaScript code, it modifies the code and generates the new code back out. Under the hood, It builds an AST, traverses it, modifies it based on the applied plugins, and then generate new code from modified AST.
Checkout this list for some more example of cross language transpilers.
Codemods
Codemods are tools to assist with large-scale codebase refactors that can be partially automated but still require human oversight and occasional intervention.
Here also, ASTs are used to replace or change code on the fly. For instance, we can replace every instance of let with const only by looking into the kind keys inside VariableDeclaration.
For Javascript, one of the famous examples is JSCodeShifts - a toolkit for running codemods over multiple JavaScript or TypeScript files.
Codemods enable Library maintainers to aid developers with the API changes they might have to do with newer version releases. ReactJs codemods containe helpful ways to upgrade the React codebase to be in sync with the latest changes.
Since Babel also provides capabilities of codemods, checkout this example that updates variable declerations to const and ensures that only var will be affected.
import { parse } from '@babel/parser';
import traverse from '@babel/traverse';
import { print } from 'recast';
const ast = parse('var foo = true;', {});
traverse(ast, {
VariableDeclaration(path) {
if (path.node.kind === 'var') {
path.node.kind = 'const';
}
}
});
const { code } = print(ast);
console.log(code); // -> const foo = true;
Intellisense
Ever wondered how IDEs are capable of producing the code hints and autocompletion when you are writing the code? AST!
Intellisense analyses the AST and, based on what you've written so far, it suggests more code that can come after that. VS code intellisense uses AI to give more meaningful results.

Static code analyzing
Static code analyzing is a method of computer program debugging that is done by examining the code without executing the program. It's done by analyzing the code against a set of coding rules. These analyzers work by running a set of rules against the compiles AST.

ESLint is a well-known Static code analyzer for Javascript. Check out this page for more info on how selectors can be exposed to query the AST.
Code formatters
Having a common style guide is valuable for a team but ensuring the same is a very painful and unrewarding process. Code formatters help dev teams enforce a similar code style by defining a common set of formatting rules.
They work by parsing the code to create the AST. Then, using this AST and the provided formatting rules, the code is re-written in a consistent and opinionated way.
One such example is Prettier which supports code formatting for a variety of languages including JavaScript, TypeScript, HTML, CSS, JSON and more. The fastest way to try out prettier would be to use the Prettier Playground.
The world of ASTs is wonderful. Next, we will focus more on the next stages of compiling pipeline with a focus on Chrome's V8 engine.